缺失值分析与处理
library(VIM)## 载入需要的程辑包:colorspace## 载入需要的程辑包:grid## VIM is ready to use.## Suggestions and bug-reports can be submitted at: https://github.com/statistikat/VIM/issues##
## 载入程辑包:'VIM'## The following object is masked from 'package:datasets':
##
## sleepdata(sleep,package = "VIM")dim(sleep)#查看数据的维度## [1] 62 10complete.cases(sleep)## [1] FALSE TRUE FALSE FALSE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
## [13] FALSE FALSE TRUE TRUE TRUE TRUE FALSE FALSE FALSE TRUE TRUE FALSE
## [25] TRUE FALSE TRUE TRUE TRUE FALSE FALSE TRUE TRUE TRUE FALSE FALSE
## [37] TRUE TRUE TRUE TRUE FALSE TRUE TRUE TRUE TRUE TRUE FALSE TRUE
## [49] TRUE TRUE TRUE TRUE FALSE TRUE FALSE FALSE TRUE TRUE TRUE TRUE
## [61] TRUE FALSEsum(complete.cases(sleep))#返回没有缺失值的样本的逻辑值,如果这个样本没有缺失的值则为true,使用sum函数整体没有缺失的样本数## [1] 42head(is.na(sleep))## BodyWgt BrainWgt NonD Dream Sleep Span Gest Pred Exp Danger
## [1,] FALSE FALSE TRUE TRUE FALSE FALSE FALSE FALSE FALSE FALSE
## [2,] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [3,] FALSE FALSE TRUE TRUE FALSE FALSE FALSE FALSE FALSE FALSE
## [4,] FALSE FALSE TRUE TRUE FALSE TRUE FALSE FALSE FALSE FALSE
## [5,] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [6,] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSEsum(is.na(sleep[1:15,]))#计算出sleep数据中前15个有NA的数量## [1] 11aggr(sleep)#缺失数据可视化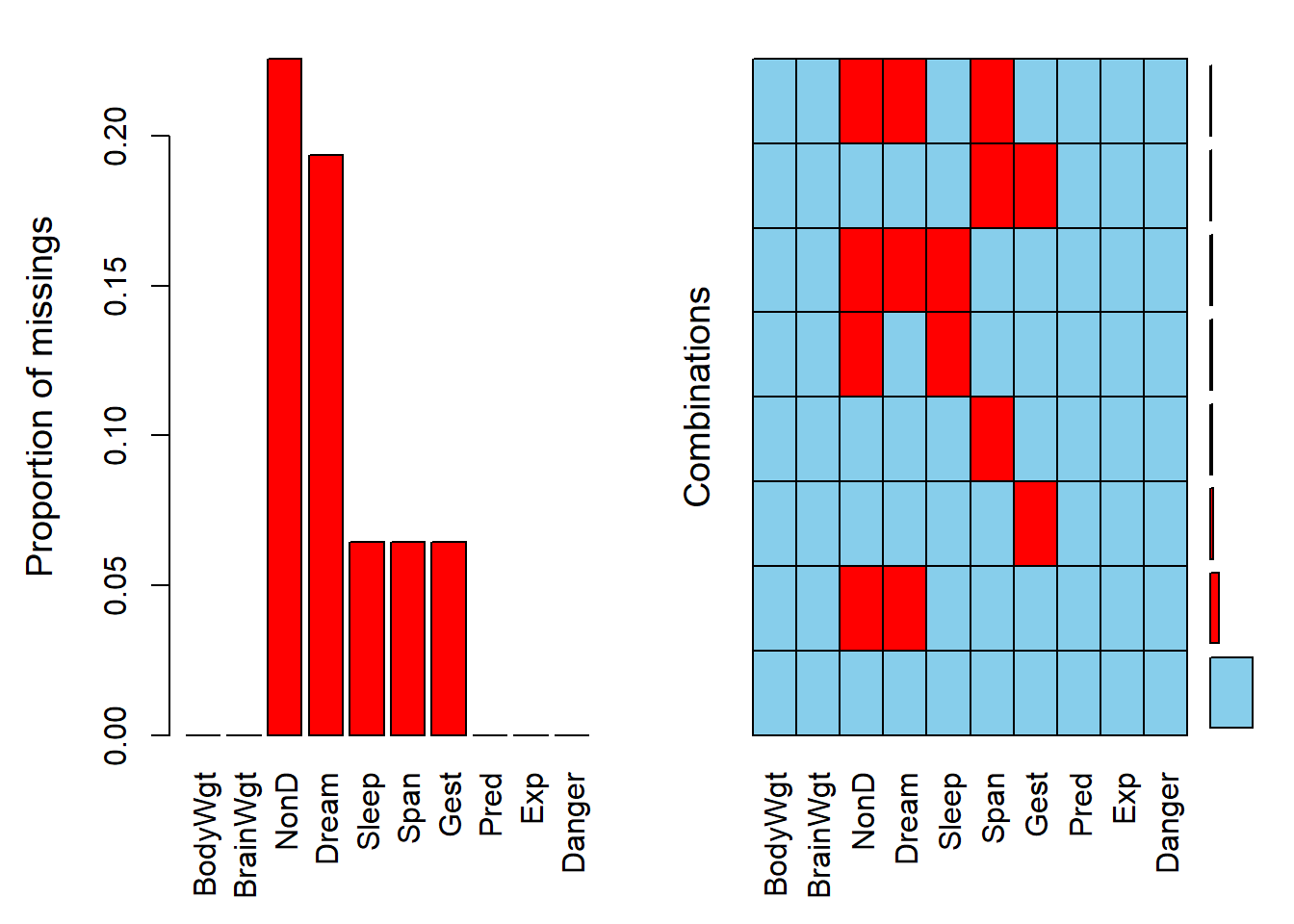
缺失数据的分布分析
library(mice)##
## 载入程辑包:'mice'## The following object is masked from 'package:stats':
##
## filter## The following objects are masked from 'package:base':
##
## cbind, rbindmd.pattern(sleep)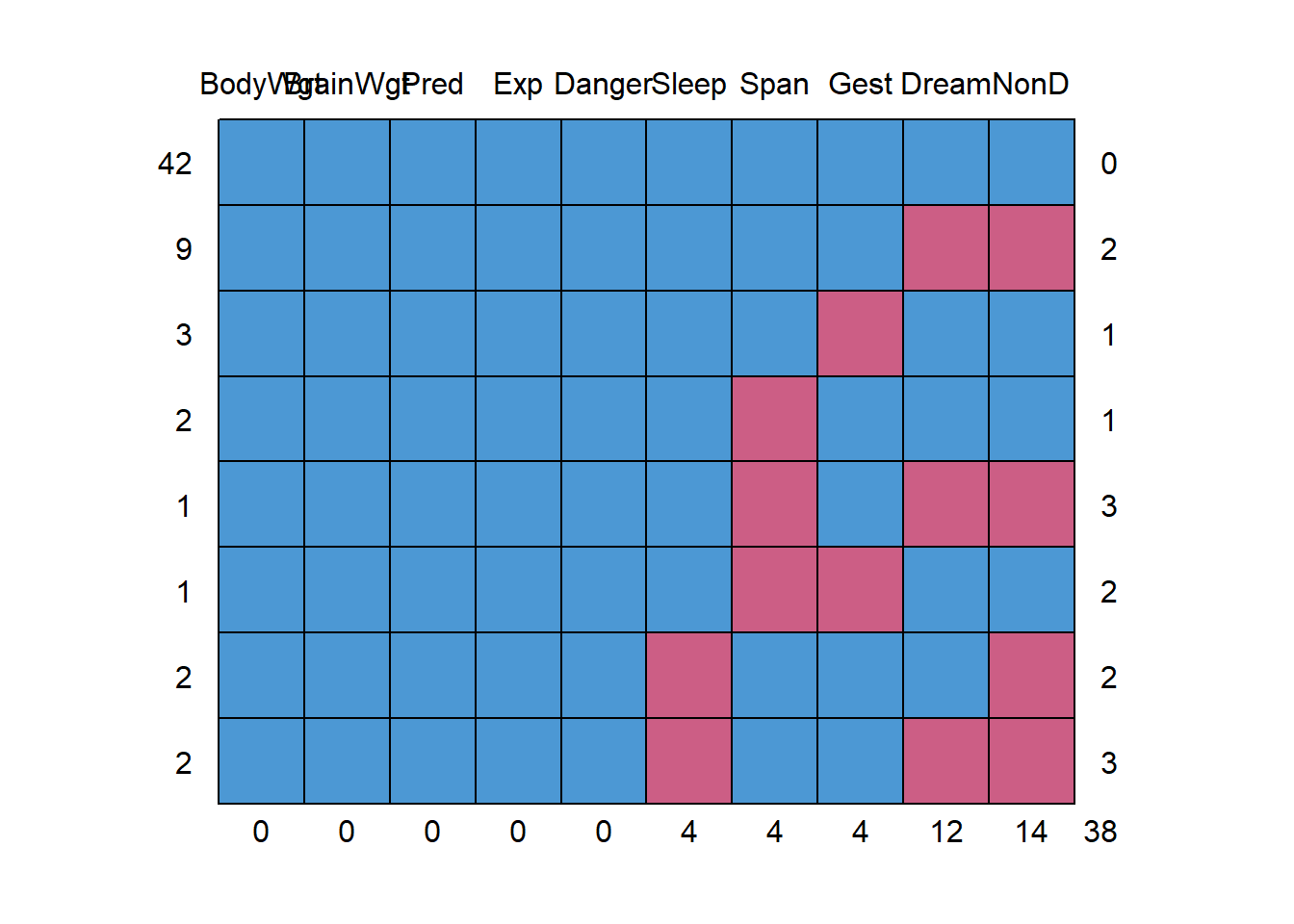
## BodyWgt BrainWgt Pred Exp Danger Sleep Span Gest Dream NonD
## 42 1 1 1 1 1 1 1 1 1 1 0
## 9 1 1 1 1 1 1 1 1 0 0 2
## 3 1 1 1 1 1 1 1 0 1 1 1
## 2 1 1 1 1 1 1 0 1 1 1 1
## 1 1 1 1 1 1 1 0 1 0 0 3
## 1 1 1 1 1 1 1 0 0 1 1 2
## 2 1 1 1 1 1 0 1 1 1 0 2
## 2 1 1 1 1 1 0 1 1 0 0 3
## 0 0 0 0 0 4 4 4 12 14 381 表示没有缺失数据,0 表示存在缺失数据,第一列第一行的 42 表示有 42 个样本是完整的,第一列最后一行的 1 表示有一个样本缺少了 Span,Dream,NonD 三个变量。 有 9 个样本缺失 Dream 和 NonD 这两个变量。
缺失数据处理
当缺失数据较少时直接删除样本。
对缺失数据进行插补。
使用对缺失数据不敏感的分析方法,例如决策树。
library(mice)
imp <- mice(sleep,seed = 1234)#插补模型,生成的是缺失数据集##
## iter imp variable
## 1 1 NonD Dream Sleep Span Gest
## 1 2 NonD Dream Sleep Span Gest
## 1 3 NonD Dream Sleep Span Gest
## 1 4 NonD Dream Sleep Span Gest
## 1 5 NonD Dream Sleep Span Gest
## 2 1 NonD Dream Sleep Span Gest
## 2 2 NonD Dream Sleep Span Gest
## 2 3 NonD Dream Sleep Span Gest
## 2 4 NonD Dream Sleep Span Gest
## 2 5 NonD Dream Sleep Span Gest
## 3 1 NonD Dream Sleep Span Gest
## 3 2 NonD Dream Sleep Span Gest
## 3 3 NonD Dream Sleep Span Gest
## 3 4 NonD Dream Sleep Span Gest
## 3 5 NonD Dream Sleep Span Gest
## 4 1 NonD Dream Sleep Span Gest
## 4 2 NonD Dream Sleep Span Gest
## 4 3 NonD Dream Sleep Span Gest
## 4 4 NonD Dream Sleep Span Gest
## 4 5 NonD Dream Sleep Span Gest
## 5 1 NonD Dream Sleep Span Gest
## 5 2 NonD Dream Sleep Span Gest
## 5 3 NonD Dream Sleep Span Gest
## 5 4 NonD Dream Sleep Span Gest
## 5 5 NonD Dream Sleep Span Gest## Warning: Number of logged events: 5fit <- with(imp,lm(Dream~Span+Gest))#with函数对对象使用函数
pooled <- pool(fit)
summary(pooled)## term estimate std.error statistic df p.value
## 1 (Intercept) 2.596689698 0.248607356 10.4449431 51.95123 2.287059e-14
## 2 Span -0.003994065 0.011692201 -0.3416008 55.64216 7.339381e-01
## 3 Gest -0.004318559 0.001458574 -2.9608093 55.15892 4.517169e-03函数 mice () 首先从一个包含缺失数据的数据框开始,然后返回一个包含多个(默认为 5 个)完整数据集的对象。每个完整数据集都是通过对原始数据框中的缺失数据进行插补而生成的。 由于插补有随机的成分,因此每个完整数据集都略有不同。with () 函数可依次对每个完整数据集应用统计模型(如线性模型或广义线性模型,最后, pool () 函数将这些单独的分析结果整合为一组结果。最终模型的标准误和 p 值都将准确地反映出由于缺失值和多重插补而产生的不确定性。 详见该篇文章
异常值分析与处理
单变量异常值检测
set.seed(2020)
x<-rnorm(100)
summary(x)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## -3.0388 -0.5620 0.1200 0.1089 0.7394 3.2016boxplot.stats(x)## $stats
## [1] -2.2889749 -0.5636108 0.1199898 0.7582063 2.4353737
##
## $n
## [1] 100
##
## $conf
## [1] -0.08885734 0.32883686
##
## $out
## [1] -2.796534 -3.038765 3.201632boxplot(x)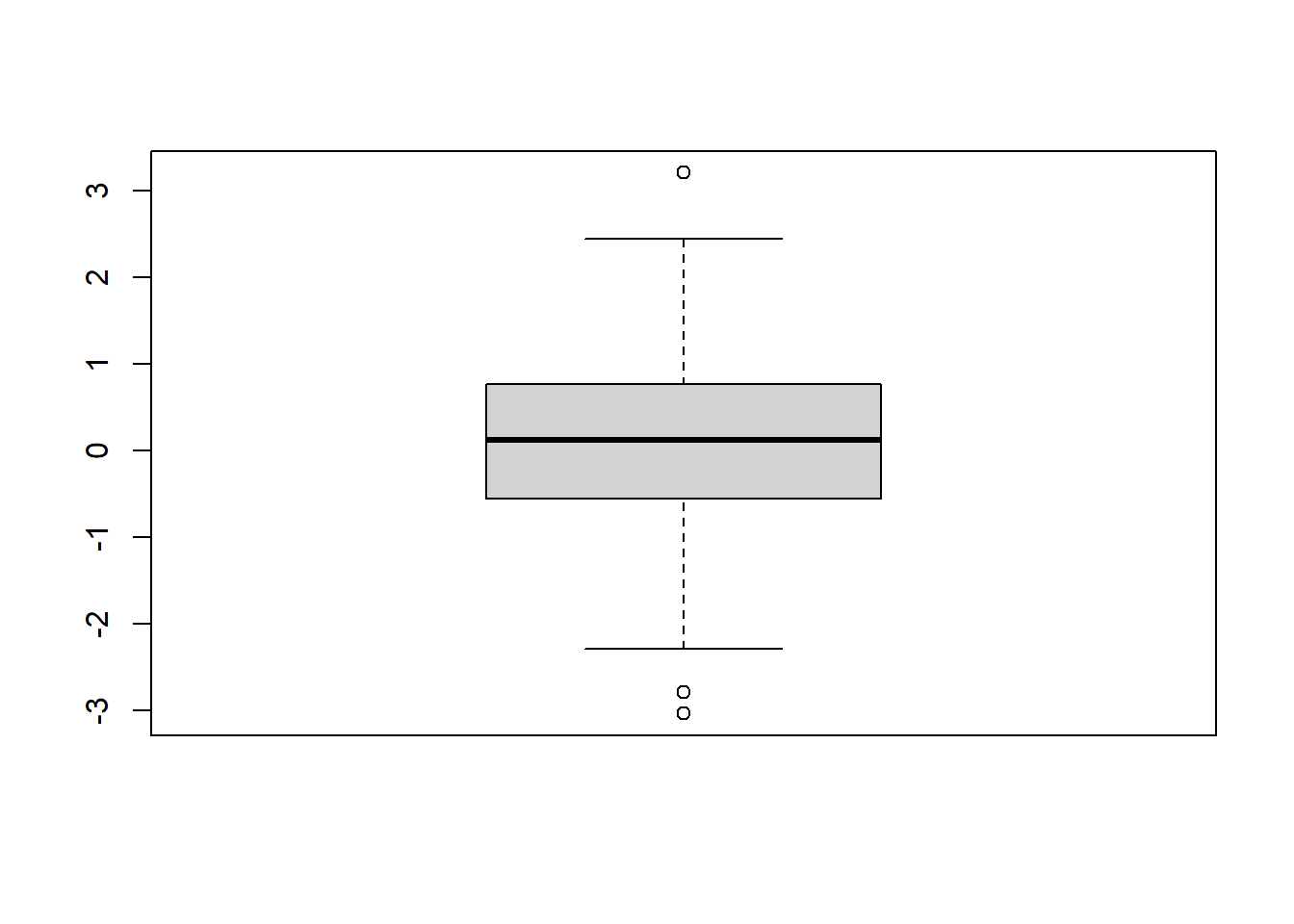
多变量异常值检测
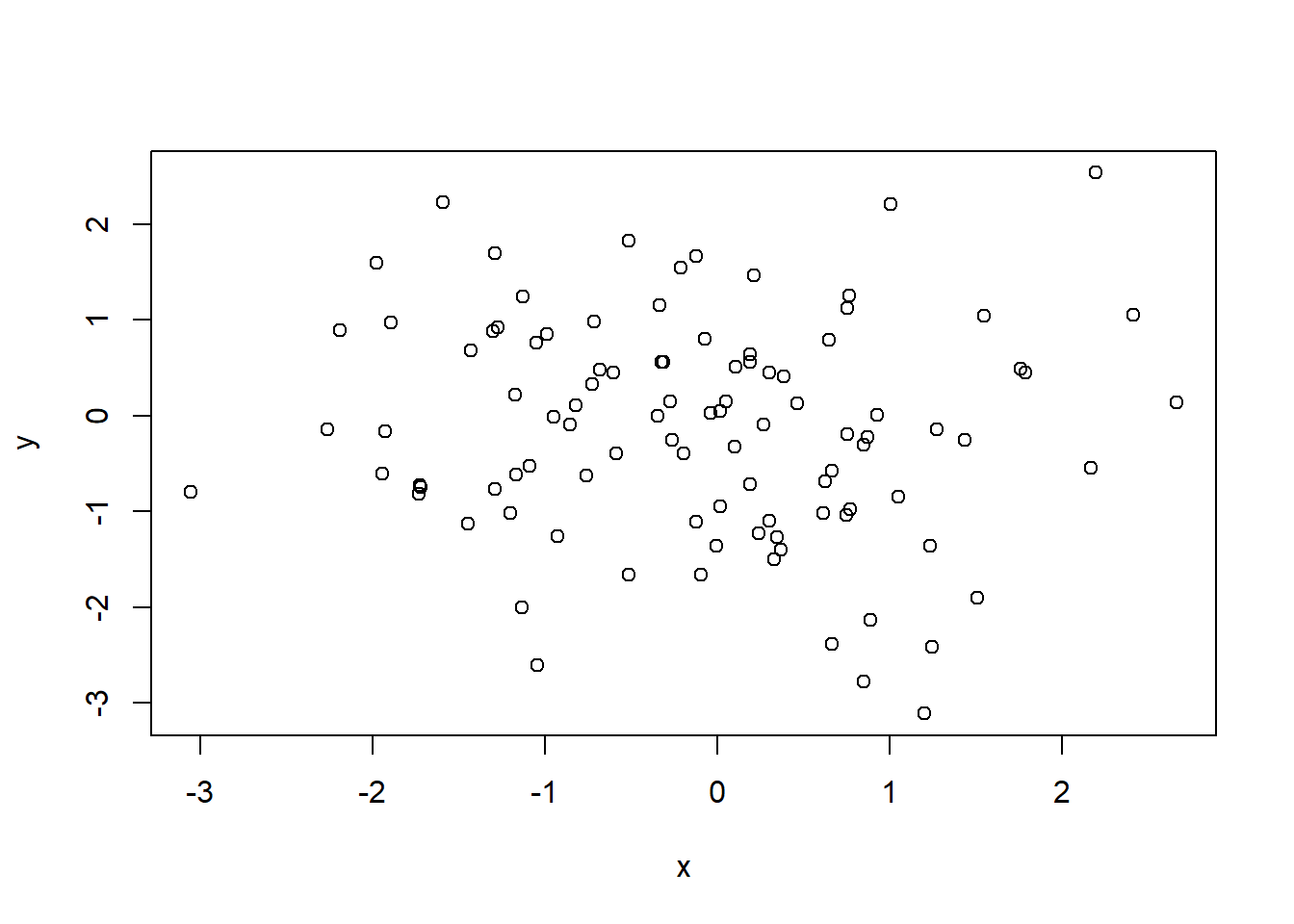
x<-rnorm(100)
y<-rnorm(100)
df<-data.frame(x,y)
head(df)## x y
## 1 -1.7287839 -0.7295331
## 2 -0.9912610 0.8513774
## 3 -0.5855056 -0.3964916
## 4 0.3835217 0.4066786
## 5 0.7466649 -1.0385534
## 6 -0.9284209 -1.2558813# 寻找x为异常值的坐标位置
(a<-which(x %in%boxplot.stats(x)$out))# 使用%in%找出x在箱线图中out的样本## integer(0)(b<-which(y %in%boxplot.stats(y)$out))## integer(0)intersect(a,b)#寻找变量x,y都为异常值的坐标位置## integer(0)plot(df)
p2<-union(a,b)#寻找变量x,y都为异常值的坐标位置
p2## integer(0)points(df[p2,],col = "red",pch = "x",cex=2)